集合(存储的是对象)
集合主要有Collection接口和Map接口派生
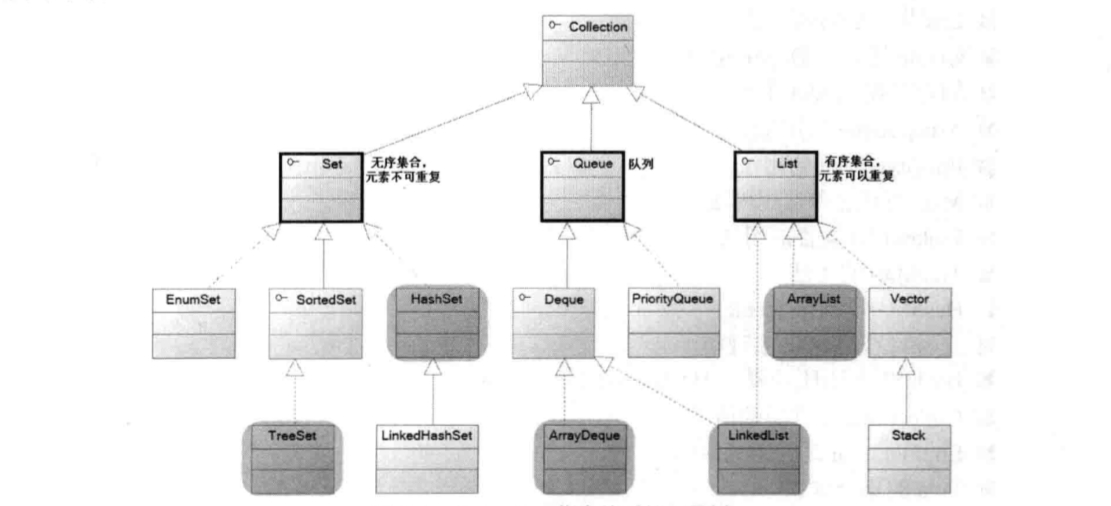
其中粗线全出的Set和List接口是Collection接口派生的两个子接口,他们分别代表了无序集合和有序集合。Queue是Java提供的队列实现。
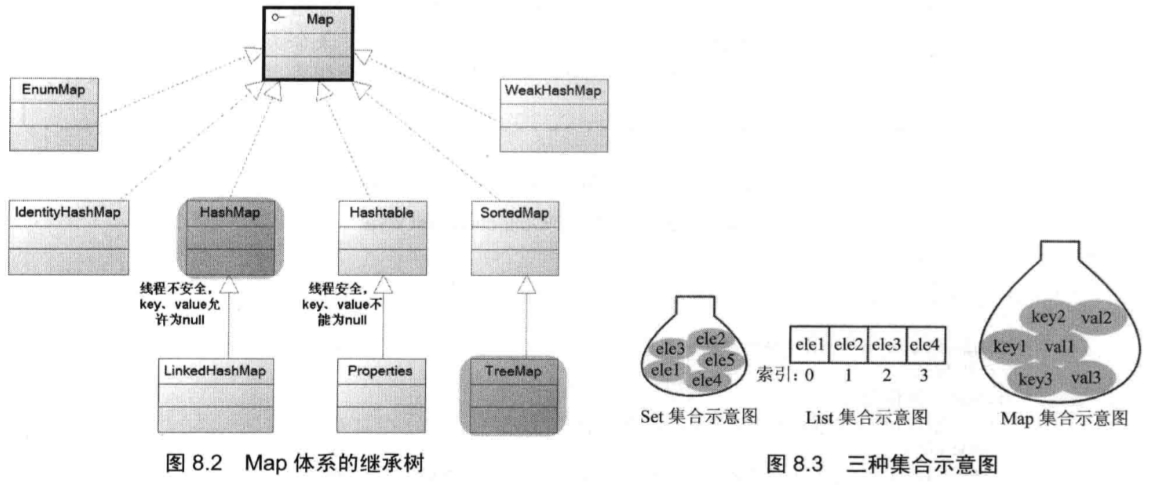
Set集合类似一个罐子,当把一个元素添加到Set中,Set集合无法记住这个元素的顺序,所以Set里的元素不能重复。List集合非常像一个数组,它可以记住每次添加元素的顺序,且List的长度可变。Map集合也像一个罐子,知识它里面的每项数据都由两个值组成。
常用的集合
HashSet,TreeSet,ArrayList,ArrayDeque,LinkedList,HashMap,TreeMap等。
Collection和Iterator
Collection
Collection是List,Set,Queue的父接口,该接口的方法适用于这几个
- boolean add (Object o):该方法用于向集合里面添加一个元素。如果集合对象被添加操作改变了返回True(所以返回类型位boolean而不是void,为的是提供一个检查Set元素是否添加成功的方式)
- boolean addAll (Collection c):该方法把集合c的所有元素添加到指定集合。如果集合对象被添加操作改变了返回True
- void clear():清楚集合里的所有元素,将长度变为0
- boolean contains(Object 0):返回集合里是否包含指定元素
- boolean contains(Collection c):返回集合里是否包含集合c里面的所有元素
- boolean isEmpty():返回集合是否为空。当长度为0时返回true,否则返回false。
- Iterator iterator():返回一个Iterator对象,用于遍历集合里面的元素。
- boolean remove(Object o):删除集合中指定元素o,当集合中包含了一个或多个o时,方法只删除第一个符合条件的元素,然后返回true。
- boolean removeAll(Collection c):从集合中删除集合c里不包含的元素(相当于把该集合变为和集合c的交集),如果该操作改变了调用该方法的集合,则返回true
- int size():该方法返回集合里的元素的个数。
- Object[] to Array():该方法把集合转换成一个数组,所有集合元素变成对应的数组元素。
Iterator
用于遍历集合元素
- boolean hasNext():如果被迭代的元素还没有被遍历完,则返回true
- Object next():返回集合里面的下一个元素
- void remove():删除集合里上一次next方法返回的元素
- void forEachRemaining(Consumer action):java8新增的默认方法,该方法可以用lambda表达式来遍历集合元素
Set
HashSet
- 元素不能重复
- 按Hash算法来存储集合中的元素
- 具有良好的存取和查找性能
- 不能保证元素的排列顺序,顺序可能与添加顺序不同
- 不是同步的,如果有两个或以上的线程同时修改HashSet,则必须通过代码来保持同步
- 集合元素可以为null
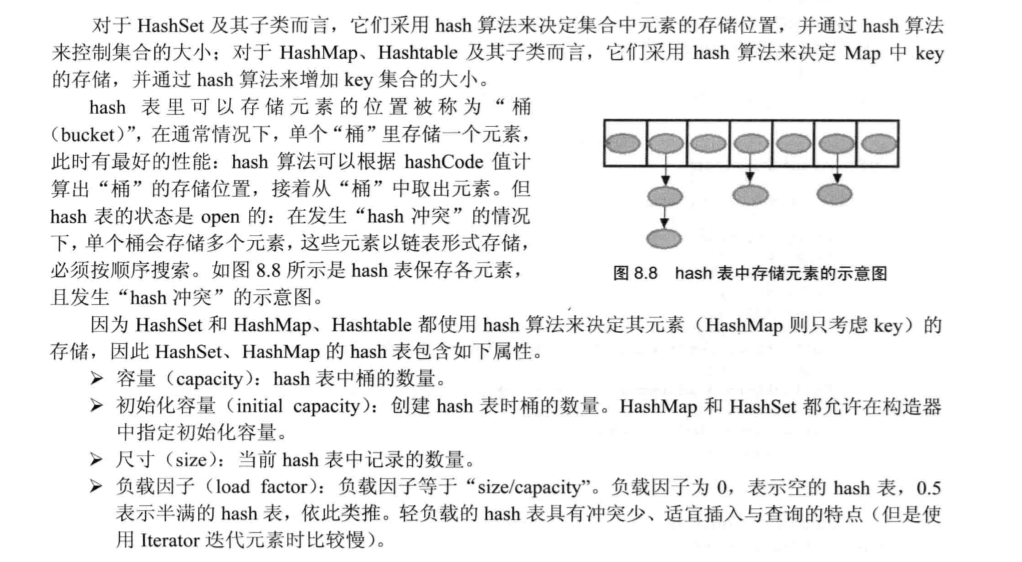
存入元素时,HashSet调用该对象的的HashCode值,然后根据他们的值决定他们HashSet中的存储位置。如果两个元素通过equals()方法比较返回true,但他们的hashCode方法的返回值不相等,HashSet将会把他存储在不同的位置,依然可以添加成功。如果hashCode相同,而equals不同,也会认为是两个对象(通过链式结构来保存多个对象)
HashSet中每个能存储元素的"槽位(slot)"通常被称为"桶"(bucket)
如果有多个元素的hashcode值相同,但他们通过equals方法比较返回false,就需要在一个“桶”
里面放多个元素,这样会导致性能下降。
重写hashcode的步骤
- 把对象内每个有意义的实例变量(即每个参与equals()方法比较标准的实例变量)计算出一个int类型的hashCode值。

注意
当程序把可变对象添加到HashCode中后,精良不要去修改集合元素参与计算hashcode和equals的实例遍历。
LinkedHashSet
- 是HashSet的子类
- 也是根据hashcode来决定元素的存储位置,但他同时使用链表来维持元素的次序。
- 性能略低于HashSet
- 虽然使用链表记录了集合元素的添加顺序,淡LinkedHashSet依然是HashSet,因此他依然不允许元素重复。
TreeSet
- 是SortedSet的实现类,TreeSet可以确保集合元素处于排序状态。
- 与,HashSet相比。TreeSet提供了几个额外的方法
- Comparator Comparator():如果TreeSet采用了定制排序,则该方法返回定制排序所使用的Comparator;如果TreeSet采用了自然排序,则返回null;
- Object first():返回集合中的第一个元素
- Object last():返回集合中的最后一个元素
- Object lower(Object e):返回集合中位于指定元素之前的元素(就是返回小于指定元素的最大值),参考元素不需要是TreeSet中的元素
- Object higher(Object e):返回集合中位于指定元素之后的元素(就是返回大于指定元素的最小值),参考元素不需要是TreeSet中的元素
- SortedSet subSet(Object fromElement , Object toElement):返回此Set的子集,范围从fromElement (包含)到 toElement(不包含)
- SortedSet headSet(Object toElement):返回此Set的子集,由小于toElement的元素组成
- SortedSet tailSet(Object toElement):返回此Set的子集,由大于toElement的元素组成
自然排序
- TreeSet放入一个对象时会调用集合元素的compareTo(Object obj)方法来比较集合元素的大小关系,然后按升序排序,这种方式就是自然排序。
- java提供了一个Compareable接口,该接口定义了一个compareTo(Object obj)方法,该方法返回一个整数值,实现该接口的类必须实现该方法。实现了该方法的对象与另一个对象进行比较的时候,比如obj1.compareTo(obj2),如果该方法返回0,说明obj1与obj2相等,如果返回一个正整数表明obj1大于obj2,如果返回一个负数,表示obj1小于obj2。

package TreeSetTest;
import java.util.TreeSet;
class Student implements Comparable {
/**
* 学生的姓名
*/
private String name;
/**
* 学生的年龄
*/
private Integer age;
/*··························
* 省略的getter和setter
*/··························
@Override
public int compareTo(Object o) {
Student student = (Student)o;
return this.getAge() > student.getAge() ? 1 :
this.getAge() < student.getAge() ? -1 : 0 ;
}
}
/**
* @author yaoqiuhong
* @create 2020-02-27 11:39
* @description
*/
public class TreeSetDemo {
public static void main(String[] args) {
// 创建一个学生对象1
Student student1 = new Student();
student1.setName("yqh");
student1.setAge(21);
// 创建一个学生对象2
Student student2 = new Student();
student2.setName("yyw");
student2.setAge(20);
// 创建一个TreeSet来存储学生对象
TreeSet treeSet = new TreeSet();
/*
* 如果Student没有实现Comparable中的compareTo方法,那么下面将Student加入
* treeSet中会出现java.lang.ClassCastException
*/
treeSet.add(student1);
treeSet.add(student2);
}
}
- 大部分对象在实现compareTo(Object obj)的时候,需要将Object对象强转成本类对象经行某个属性的比较。而又由于在向TreeSet中添加元素的时候会通过compareTo(Object obj)方法来比较,所以在向其中添加不同类的对象的时候,也会引发java.lang.ClassCastException.所以需要注意的是:向TreeSet中添加的应该是同一个类的对象。
- 当把一个对象加入TreeSet集合中,TreeSet调用该对象的compareTo(Object obj)方法跟其他对象比较大小,然后根据红黑树结构找到他的存储位置。如果两个对象根据compareTo(Object obj)方法返回的值为0,新对象将无法添加到TreeSet中。
- 对于TreeSet而言,他判断两个对象是否相等的唯一标准是:两个对象通过compareTo(Object obj)比较返回的值是否为0,如果为0,就认为相等,如果不为0,就认为不相等。
- 当需要把一个类的对象放到TreeSet中时,应该保证该类中的compareTo(Object obj)返回0时 ,他的equals()方法返回true 。
- 当改变了TreeSet集合里添加的元素的属性后,这将导致它与其他对象的大小顺序发生了变化,淡TreeSet不会再次调整他们的顺序,甚至导致TreeSet中保存的这两个对象通过compareTo(Object obj)方法比较返回0。(正常情况下,为0时,后一个不会被插入)
- 当TreeSet中的元素的属性(跟compareTo方法中的比较有关的字段)有被修改过后,那么被修改的属性就不能对修改过的元素进行
remove操作。只能对没有改变的元素进行remove操作。值得注意的是:对没有被修改的的元素进行remove操作后,TreeSet会对集合中的元素从新索引(不是从新排序),接下来就可以删除TresSet中的所有元素了。
定制排序
- TreeSet的自然排序是根据集合元素的大小,TreeSet将他们以升序排序,如果要实现定制排序,例如通过降序排序(当然自然排序通过反写compareTo方法的比较逻辑也可以实现),则可以通过Comparator接口的帮助。该接口里面包含一个 int commpare(T o1, T o2 )方法,该方法用于比较o1和o2的大小。如果该方法返回0,说明o1与o2相等,如果返回一个正整数表明o1大于o2,如果返回一个负数,表示o1小于o2。
- 如果需要实现定制排序,则需要在创建TreeSet集合对象的时候,提供一个Comparator对象与TreeSet集合关联,由该Comparator对象负责集合元素的排序逻辑。由于Comparator时一个函数式接口,因此可使用lambda表达式来替代Commparator
- 同样不可以插入相同的元素,不然会由ClassCastException异常
package TreeSetTest.TreeSetTest;
import java.util.TreeSet;
class Persion {
/**
* 人的姓名
*/
private String name;
/**
* 人的年龄
*/
private Integer age;
/*··························
* 省略的getter和setter
*/··························
@Override
public String toString() {
return "Persion{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
}
/**
* @author yaoqiuhong
* @create 2020-02-27 14:15
* @description
*/
public class TresSetTest {
public static void main(String[] args) {
// 创建对象人1
Persion persion1 = new Persion();
persion1.setName("YQH");
persion1.setAge(21);
// 创建对象人2
Persion persion2 = new Persion();
persion2.setName("YYW");
persion2.setAge(20);
//创建TreeSet对象
TreeSet treeSet = new TreeSet((o1,o2) ->{
Persion p1 = (Persion)o1;
Persion p2 = (Persion)o2;
return p1.getAge() < p2.getAge() ? 1 :
p1.getAge() > p2.getAge() ? -1 : 0 ;
});
treeSet.add(persion1);
treeSet.add(persion2);
System.out.println("21"+((Persion)treeSet.first()).getAge());
}
}
EnumSet
- 是一个专门为枚举设计的集合类,EnumSet中的所有元素都必须时指定枚举类型的指定值。该枚举类型是在创建EnumSet时显示或隐式地指定。Enum的集合元素也是有序的,EnumSet以枚举值在Enum类内定义顺序来决定集合元素的顺序
- 以位向量的形式存储,这种存储形式非常紧凑,高效,英雌EnumSet都西昂占用内存很小,而且运行效率很好。尤其是进行批量操作(如调用containsAll()和retainAll方法)时,如果参数也是EnumSet集合,则该批量操作的执行速度也非常快。
- 不允许加入null元素,如果试图插入null元素,EnumSet将抛出NullPointerException异常。如果是想判断EnumSet是否包含null元素或试图删除null元素都不会抛出异常,只是删除操作将返回false。
- 没有提供构造器来创建该类的实例,程序应该通过他提供的类方法来创建EnumSet。Enum提供了如下常用方法来创建EnumSet对象。
- EnumSet allOf(Class elementType):创建一个包含指定枚举类型所有枚举值的EnumSet集合。
- EnumSet complementOf(EnumSet s):创建一个其元素类型与指定EnumSet里元素类型相同的EnsumSet集合,新EnsumSet集合包含原EnumSet集合所不包含的,此枚举剩下的枚举值(即新的EnumSet集合和原集合的集合元素加起来就是该枚举类的所有枚举值)
- EnumSet copyOf(Collection c):使用一个普通集合来创建EnumSet集合
- EnumSet copyOf(EnumSet s):创建一个与指定EnumSet具有相同元素类型,相同集合元素的EnumSet集合
- EnumSet noneOf(Class elementType):创建一个元素类型为指定枚举类型的空EnumSet。
- EnumSet of(E first, E... rest):创建一个包含一个或多个枚举值的EnumSet集合,传入的多个枚举值必须属于同一个枚举类
- EnumSet range(E from, E to):创建一个包含从from枚举值到to枚举值范围内所有枚举值EnumSet集合。
package enumSetTest;
import java.util.Collection;
import java.util.EnumSet;
import java.util.HashSet;
/**
* 季节枚举类
* */
enum Season{
SPRING(1),SUMMER(2),FALL(3),WINTER(4) ;
/**
* 季节的代码
* */
private int code;
Season(int code){
this.code = code ;
}
public int getCode(){
return code;
}
}
/**
* @author yaoqiuhong
* @create 2020-02-27 20:26
* @description
*/
public class EnumSetTest {
public static void main(String[] args) {
// 通过allOf(Class elementType)创建一个Season类型全部枚举值的EnumSet
EnumSet enumSet1 = EnumSet.allOf(Season.class);
System.out.println("enumSet1:" + enumSet1);
// 通过noneOf(Class elementType)创建个Season类型的空EnumSet
EnumSet enumSet2 = EnumSet.noneOf(Season.class);
System.out.println("enumSet2:" + enumSet2);
// 添加Season的元素到EnumSet中
enumSet2.add(Season.WINTER);
enumSet2.add(Season.SUMMER);
System.out.println("enumSet2:" + enumSet2);
// 通过of(E first, E... rest)指定枚举值创建Season类型的EnumSet
EnumSet enumSet3 = EnumSet.of(Season.SUMMER , Season.WINTER);
System.out.println("enumSet3:" + enumSet3);
// 通过range(E from, E to)创建一个从SPRING到WINTER的EnumSet
EnumSet enumSet4 = EnumSet.range(Season.SUMMER , Season.WINTER);
System.out.println("enumSet4:" + enumSet4);
// 通过complementOf(EnumSet s)创建一个enumSet4的补集的EnumSet
EnumSet enumSet5 = EnumSet.complementOf(enumSet4);
System.out.println("enumSet5:" + enumSet5);
// 创建一个元素为Season值得HashSet
Collection c = new HashSet();
c.add(Season.SUMMER);
c.add(Season.WINTER);
// 通过copyOf(Collection c)来复制c中的所有元素来创建一个EnumSet(Collection对象c中的所有元素都必须是同一个枚举类的枚举值)
EnumSet enumSet6 = EnumSet.copyOf(c);
System.out.println("c:"+c+" enumSet6:"+enumSet6);
// 通过copyOf(EnumSet s)复制一个EnumSet
EnumSet enumSet7 = EnumSet.copyOf(enumSet6);
System.out.println("enumSet6:"+enumSet6+" enumSet7:"+enumSet7);
}
}
各个Set得得性能比较
- HashSet得性能总比TreeSet好(特别是最仓用类得添加/查询元素等操作)因为TreeSet需要额外得红黑树算法来维护集合得次序。只有当需要一个保持排序得Set时,才应该使用TreeSet。
- LinkedHashSet对于普通的插入,删除操作,LinkedHashSet比HashSet要略慢一点,这是由于维护链表所带来的额外开销造成的,但由于有了链表,遍历LinkedHashSet更快。
- EnumSet是所有Set实现类中性能最好的。但他只能保持同一个枚举类的枚举值作为集合元素
- Set的三个实现类,HashSet,TreeSet,enumSet都是线程不安全的。
List
- List也是Collection的子接口,可以使用所有Collection中的方法。而且由于List是有序集合,英尺List集合增加了一些感觉索引来操作集合的方法。
- void add(int index , Object element):将元素element插入到index处
- boolean addAll(int index , Collection c):将集合c所包含的所有元素插入到List集合的index处
- Object get(int index):返回集合index索引处的元素
- int indexOf(Object o):返回对象o在List集合中第一次出现的位置
- int lastIndex(Object o):返回对象o在List集合中最后一次出现的位置
- Object remove(int index):删除并返回Index处的元素
- Object set(int index , Object element):将index索引处的元素替换成element对象,返回被替换的旧元素。(只能改变,不能向后面添加)
- List subList(int formIndex , int toIndex):返回从索引formIndex(包含) 到索引toIndex(不包含)的所有元素组成的子集合
- void replaceAll(UnaryOperator operator):根据operator指定的计算规则重新设置List集合的所有元素
- void sort(Comparator c):根据Comparator参数对List集合的元素排序。
通过equals()方法来判断两个元素是否相等。
replaceAll和sort的演示
package List;
import java.util.ArrayList;
import java.util.List;
/**
* @author yaoqiuhong
* @create 2020-02-27 23:19
* @description
*/
public class ListTest {
public static void main(String[] args) {
// 创建List对象
List list = new ArrayList();
/*
* 添加元素
* */
list.add("如果那两个字");
list.add("没有颤抖");
list.add("我不会发现");
list.add("我难受");
System.out.println("list中元素插入顺序:"+list);
// 使用Comparator的lambda表达式对List集合排序
list.sort(((o1, o2) -> {
String s1 = (String)o1;
String s2 = (String)o2;
return s1.length() - s2.length();
}));
System.out.println("list中元素通过sort排序后顺序:"+list);
// 使用Lambda表达式控制使用每个字符串的长度作为新的元素集合
list.replaceAll(ele -> ((String)ele).length());
System.out.println("list中元素通过replaceAll替换后元素为:"+list);
}
}
ListIterator
与Set只提供一个Iterator不同,List还额外提供一个ListIterator方法,该方法返回一个ListIterator对象,ListIterator接口继承了Iterator接口,提供了专门操作List的方法。ListIterator接口在Iterator接口上增加了一下方法。
- boolean haspervious():返回该迭代器关联的集合是否还有上一个元素
- Object previous():返回该迭代器的上一个元素
- void add(Object o):在指定位置插入一个元素
ListIterator相比于Iterator增加了向前迭代的功能(Iterator只能向后迭代)。而且ListIterator还能通过add()方法向List中添加元素(Iterator只能删除元素)
ArrayList and Vector
- 都是基于数组实现的List类,所以ArrayList和Vector类都封装了一个动态的,允许再分配的Object[]数组。
- 使用initialCapacity参数来设计该数组的长度,当向ArrayList or Vector 添加的元素超过了数组的长度的时候,ArrayList或Vector的initialCapacity会自动增加。
- 对于普通场景,我们无需关心initialCapacity的大小。但如果向ArrayList or Vector添加大量元素的时候,可以使用ensureCapacity( int minCapacity)方法一次性地增加initialCapacity。这就可以减少分配的权重,从而提高性能!
- 如果创建空的ArrayList or Vector 时没有指定initialCapacity参数,则Object[]数组的长度默认为10
- void ensureCapacity( int minCapacity):将ArrayList or Vector集合时的Object[]数组长度增加大于或等于minCapacity值。
- void trimToSize():调整ArrayList or Vector集合的Object[]数组的个数为当前元素的个数。该方法可以减少集合占用的存储空间。
- ArrayList or Vector 的显著区别就是:ArrayList时线程不安全的,Vector则是线程安全的。这里需要注意即使要保证ArrayList时线程安全的,也不推荐使用Vector。这时候可以使用Collections工具类,它可以将一个ArrayList变成线程安全的。
Stack
- Vector还提供一个Stack子类,它用于模拟"栈"这种数据结构。与其他集合一样,进栈出栈的元素都是Object,因此从栈中取出元素后必须进行类型转换,除非你只是使用Object具有的操作。提供的方法
- Object peek():返回"栈"的第一个元素,但并不将该元素"pop"出栈
- Object pop():返回"栈"的第一个元素,但并将该元素"pop"出栈
- void push(Object item):将一个元素"push"进栈,最后一个进"栈"的元素总是位于"栈"顶
- 跟Vectors是一个较老的类,它同样是线程安全的,性能较差的。因此应该少用Stack,如果需要用"栈"这种数据结构,则可以考虑使用 ArrayDeque
Arrays.ArrayList
-
有一个操作数组的工具类:Arrays,该工具类里提供了asList(Object... a)方法,该方法可以把一个数组或指定个数的对象转换成一个List集合,这个List集合既不是ArrayList实现类也不是Vector的实现类,而是Arrays的内部类ArrayList的实例。
-
Arrays.ArrayList是一个固定长度的List集合,程序只能遍历访问该集合的元素,不可台南佳,删除该集合里的元素。
package arrays;
import java.util.Arrays;
import java.util.List;
/**
* @author yaoqiuhong
* @create 2020-02-28 00:36
* @description
*/
public class ArraysDemo {
public static void main(String[] args) {
// 利用Arrays.asList获取List
List list = Arrays.asList("如果那两个字","没有颤抖","我不会发现我难受");
System.out.println(list);
// 遍历元素
list.forEach(System.out::println);
// 试图增加,删除元素都会引发UnsupportedOperationException异常
list.add("增加元素会抛出UnsupportedOperationException异常");
list.remove("移除元素会抛出UnsupportedOperationException异常");
}
}
Queue
- 用于模拟队列这种数据结构(元素先进先出)
- 新元素插入(offer)到队列的尾部,访问元素(poll)操作会返回队列头部的元素。筒仓,队列不允许所及访问队列中的元素
- 定义了如下方法:
- void add(Object e):将指定的元素加入此队列的尾部
- Objec element():获取队列头部的元素,但是不删除该元素
- boolean offer(Objec e):将指定元素加入此队列的尾部。当使用有容量限制的队列时,此方法通常比add(Object e)方法更好。
- Objec peek():获取队列头部的元素,但是不删除该元素。如果队列为空,返回null
- Objec poll():获取队列头部的元素,并删除该元素,如果此队列为空,则返回null
- Objec remove():获取队列头部的元素,并删除该元素
- Queue有一个PriorityQueue实现类。除此之外,Queue还有一个Deque接口,Deque代表一个“双端队列”,双端队列可以同时从两端来添加,删除元素,因此Deque的实现类即可以当成队列使用,也可当成栈使用。java为Deque提供了ArrayDeque和LinkedList两个实现类
PriorityQueue
- 不按元素的插入顺序保存元素,二十按元素的大小从新排序,因此通过peek()方法或者poll方法取出队列中的元素时,并不是去除最先进入的元素而是取出最小的元素。
- 不允许插入null元素
- 两种排序
- 自然排序:元素实现Comparable接口
- 定制排序:创建PriorityQueue队列时,闯入一个Comparaor对象。
- PriorityQueue对元素的要求与TreeSet对元素的要求基本一致。
Deque接口与ArrayDeque实现类
LinkedList
LinkedList是List接口的实现类,可以根据索引来随机访问集合中的元素。与此同时,LinkedList海慧寺心安了Deque接口,可以被当成双端队列来使用。

各种线性表的性能分析

Map
- Map用于保存具有映射关系的数据,Map里面保存着两组值,以组值用于保存Map里的Key,另外一组值用于保存Map里的Value,key和value都可以是任何类型的数据。Map的Key不允许重复,即同一个Map的两个key通过equals方法总是返回false。
- key和value是一对一的关系,即通过指定的key,总能找到唯一的,确定的value。如果把Map的两组值拆开来看:
- Map里面的所有Key放在一起来看,他们就组成了一个Set集合(所有Key没有顺序,key与key之间不能重复)实际上map里面确实包含了一个KeySet方法,用于返回Map里面所有Key组成的Set集合
- Set与Map的关系十分密切,虽然Map中放的元素是Key-value对,Set集合中存放的元素是单个对象,但如果把Key-value对中的value当成key的附庸:key在哪里,value就在哪里。这样就可以对待Set一样来对待Map了。事实上Map提供了一个Entry内部类来封装Key-Value对,而计算Entry存储时只考虑Entry封装的Key。从Java的源码来看,java先是实现了Map,然后通过包装一个所有Value都为null的Map就实现了Set集合。
- Map里面的所有Value放在一起来看,他们又非常类似一个List:元素与元素之间可以重复,每个元素可以根据索引来查找,知识Map中的索引不再使用整数值,而是使用另一个对象作为索引。如果要从List集合去除元素,则需要提供该元素的数字索引;如果需要重Map里面取出元素,则需要提供该Value的Key索引。因此,Map有时候也被称为字典,或者关联数组。
- Map提供了如下接口
- void clear():删除该Map对象中的所有Key-value对
- boolean containsKey(Object key):查询Map中是否包含指定的Key,如果包含返回True
- boolean containsValue(Object value):查询Map中是否包含一个或者多个的value,如果包含返回True
- Set entrySet():返回Map中包含的Key-value对所组成的Set集合,每个集合元素都是Map.Entry(Entry是Map的内部类)对象
- Object get(Object key):返回指定的key所对应的value,如果此Map中不包含该Key,则返回null
- boolean isEmpty():查询该Map是否为空(即不包含任何的Key-value对)如果为空则返回true
- Set ketSet():返回该Map中所有key组成的Set集合
- Object put(Object key , Object value):添加一个Key-value对,如果dangqianMap中已有一个与该Mao相等的Key-value对,则新的Key-value对会覆盖原来的Key-value对。
- void putAll(Map m):将指定的Map中的Key-value对复制到本Map中
- Object remove(Object key):删除指定的key-value对,返回被删除key所关联的value,如果该key不存在,则返回null
- boolean remove(Object key , Object value):java8新增的方法,删除指定key,value所对应的key-value对。如果删除成功,返回会true,否者返回false
- int size():返回该Map中的key-value的个数
- Collection values():返回该Map里所有value组成的Collection
Entry
- 是Map集合的一个内部类,该类封装了一个key-value对。Entry包含如下三个方法
- Object getKey():返回该Entry中包含的key值
- Object getValue():返回该Entry里包含的Value值
- Object setValue(V value):设置该Entry里包含的Value值,并返回新设置的value值。
HashMap and Hashtable
- Hashtable线程安全,HashMap 线程不安全
- Hashtable不允许使用null作为key和value。Hashtable允许使用null作为key和value(由于Map的key不能重复,所以HashMap里最多只有一个key-value对的Key为null。)
- 为什么是Hashtable而不是HashTable。Hashtable是一个很老的类,它的命名甚至没有遵守Java的命名规范:每个单词的首字母都应该大写。(后来大量的程序中使用了Hashtable,所以这个类名就没修改为HashTable)
- 为了成功的在HashMap,Hashtable中存储,获取对象,用作Key的对象必须实现HashCode方法和equals方法。判断两个Key是否相等的标准 是:通过equals()方法比较返回true,两个key的hashCode值也相等。判断两个value是否相等的标准:通过equals方法比较返回true。
- 与HashSet一样,如果使用可变对象作为HashMap的key,并且修改了作为Key的可变对象,那么就会出现与HashSet一样的情形。
LinkedHashMap
- 与HashSet有一个LinkedHashSet子类类似,HashMap也有一个LinkedHashMap子类:LinkedHashMap也是使用双向链表来维护key-value对的顺序(只需要考虑key的次序).
- 使用LinkedHashMap可以避免对HahMap,Hashtable里的key-value排序(只需要插入的时候保持顺序即可),同时又可避免使用TreeMap所增加的成本。
- 性能略低于HashMap
Properties
TreeMap
- 是SortedMap接口的实现类。TreeMap就是一个红黑树结构,每个key-value对即作为红黑树的一个节点。TreeMap存储key-value对,树妖对key节点进行排序。排序方法有两种。自然排序和定制排序(与TreeSet相似)

WeakHashMap
与HashMap类似,与HashMap的区别在于HashMap的key保留了实际对象的强引用,这意味着,只要HashMap对象不被销毁,该HashMap的所有key所引用的对象就不会被垃圾回收,HashMap也不会自动删除这些key对应的key-value对:但WeakHashMap的key只保留了实际对象的弱引用,这意味着WeakHashMap对象的key所引用的对象没有被其他强引用变量所引用,则这些key所引用的对象可能被垃圾回收,WeakHashMap也可能自动删除这些key对应的key-value对。
IdentityHashMap
与HashMap类似,与HashMap的区别在于,它在处理两个key相等时比较特殊,在IdentityHashMap中,当且仅当两个key严格相等(key1 == key2)时,IdentityHashMap才会认为两个key相等。
EnumMap
- EnumMap内部以数组形式保存
- EnumMap根据key的自然顺序(即枚举值中的定义顺序)来维护key-value对的顺序。
- 不允许使用null作为key,但允许null作为value。如果试图使用null插入key,那么就会抛出NPE。如果只是查询是否包含null或者只是删除值为null的key,那么都不会抛出NPE
- 创建一个EnumMap必须指定一个枚举类。
EnumMap enumMap = new EnumMap(EnumClassName.class)
各Map的性能分析
- HashMap通常比Hashtable要快(Hashtable是一个古老并且线程安全的集合)
- TreeMap通常比HashMap,Hashtable要慢(尤其在插入,删除时更慢),应为TreeMap使用红黑树管理key-value对(红黑树的每个节点都是一个key-value对)
- 使用TreeMap的好处是可以让Key-value对总是处于有序状态,无需专门排序。当TreeMap被填充后,就可以调用keySet,取得由key组成的Set,然后使用toArray()方法生成Key的数组。接下来使用Arrays的binarySearch()方法在已排序的数组中快速的查询对象
- LinkedHashMap比HashMap要慢一点,因为他需要维护链表来保持Map中Key-value时的添加顺序
- 一般建议使用HashMap,因为HashMap就是为快速查询设计的(HashMap地城其实也是采用数组来存储key-value对)
HashMap与HashSet性能比较

Collections
排序
- void reverse(List list):反转指定List集合中元素的顺序
- void shuffle(List list):对List集合进行随机排序
- void sort(List list):根据元素的自然顺序对List集合的元素按升序排序
- void sort(List list , Comparator c):根据指定的Comparator产生的顺序对List集合元素进行排序
- void swap(List list, int i, int j):将指定List集合中的i处元素和j处元素进行交换
- void rotate(List list, int distance):当distance为正数时,将list集合的后distance各元素“整体”移到前面。当distance为负数时,将list集合的前distance各元素整体移到后面
查找替换
- int binarySerach(List list , Object key):使用二分法搜索指定的List集合,以获得指定对象在List集合中的索引。如果要使该方法可以正常工作,则必须保证List中的元素已经处于有序状态。
- Object max(Collection coll):根据元素的自然顺序,返回给定集合中的最大元素
- Object max(Collection coll , Comparator comp):根据Comparator指定顺序,返回给定集合中的最大元素
- Object min(Collection coll):根据元素的自然顺序,返回给定集合中的最小元素
- Object min(Collection coll , Comparator comp):根据Comparator指定顺序,返回给定集合中的最小元素
- void fill(List list , Object obj):使用指定元素obj替换指定List集合中的所有元素
- int frequency(Collection c , Object o):返回指定集合中指定元素出现次数
- int indexOfSublist(List source , List target):返回子List对象在父List对象中第一次出现的位置索引:如果父List中没有出现这样的子List,则返回-1
- int lastIndexOfSublist(List source , List target)返回子List对象在父List对象中最后一次出现的位置索引:如果父List中没有出现这样的子List,则返回-1
- boolean replaceAll(List list ,Object oldVal ,Object newVal):使用一个新值newVal替换LIst对象的所有旧值oldVal
同步控制
- Collection类中提供了多个
synchronizedXxx()方法,该方法可以将只当集合包装成线程同步的集合,从而解决并发访问集合时的线程安全问题
- java中常用的集合的实现类HashSet,TreeSet,ArrayList,ArrayDeque,LInkedList,HashMap和TreeMap都是线程不安全的。
- Collection可以通过
Collection c = Collections.synchronizedCollection(new Collection实现类) 创建对应的线程安全版本
- List可以通过
List list = Collections.synchronizedList(new List实现类)创建对应的线程安全版本
- Map可以通过
Map map = Collections.synchronizedMap(new Map实现类)创建对应的线程安全版本
- Set可以通过
Set set = Collections.synchronizedSet(new Set实现类)创建对应的线程安全版本
设置不可变集合
-
emptyXXX():返回一个空的,不可变的集合对象,此处的集合既可以是List,也可以是SortedSet。Set,还可以时Map,SortedMap
-
singletonXXX():返回一个只包含指定对象(只有一个或一项元素)的,不可变的集合对象,此处的集合即可以时List,也还可以是Map
-
unmodifiableXxx():返回指定集合对象的不可变试图,此处的集合计可以是List,也可以是Set。SortedSet,还可以是Map。SortedMap等。
-
上面三个方法的参数都是原有的集合类型,返回值是该集合的“只读”版本。如果对其修改则会出现UnsupportedOperationException异常。